mudmanc4
-
Posts
14,876 -
Joined
-
Last visited
-
Days Won
230 -
Speed Test
My Results
Everything posted by mudmanc4
-
1 gig fiber Buckeye ?
-

Anyone getting 1000Mbps from Spectrum...not me!
mudmanc4 replied to MFP21's topic in Show off your speed
I've been loosely following this thread. Not read it all. Keeping this in mind.......... Everything Microsoft has very serious fatal issues. I left Windows after they torched NT/ 2k , everything since stinks on ice with a laser show, on the best brand new shiny hardware with the latest in connection technology. Although I am still forced to deal with it. MS Enterprise is a dumpster fire behind a back water New York City greasy spoon on life support with krok'd out staff. Now that this is out of the way and likely has nothing to do with the topic ......... ----------------------------------------------------------------------------------------- No idea if this has been mentioned in this thread so forgive me, if it were me, first thing I might do is remove all possible hops on internal network. Remove any and all 'other' devices from the local network. Test different times of the day in that setup. I would chill, because I have been around the Sun enough times to know the likelihood of my systems achieving what any ISP sells me are slim. And make the best of what I can do with what I have been granted. Paying for or not. Aside this, if I require a 1 gig service to be 1 gig constantly, then I would get setup with a business account, because I would never fully utilize 1 Gig in my residence unless I was testing for it. Not the way streaming media is setup. Not the way anything residential is setup as far as I am aware. I might go find a local acquaintance and setup an iPerf server between. -
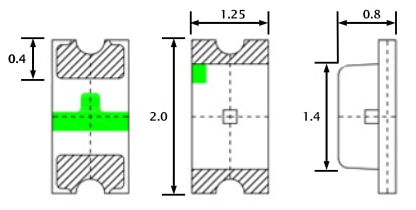
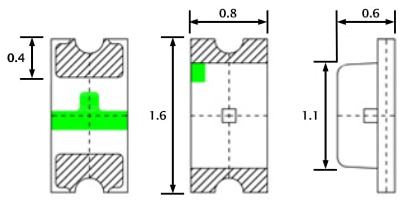
After a couple years the blue LED in the AP-Pro's withered to a mere shadow, not that this really matters for functionality, but it does. It's a status report. Anyway I searched around to find the next size up from the 0603 which appear to be the original size, both the 0805 and the 0603 rates ~3v@ 20Ma. I opted to use the larger of the two. The size of the 0805 claims 2/1.25/.8 mm, where the 0603 sits 1.6/.8/.6 For reference here is the 0805 in my hand , and on a Lowe's gift card. The Anode (+) is the green mark. The job could have used a solder tip 1/4 of the smallest size I had which was ~1.5mm, as well the solder could have been 0.3mm Vs. 0.6mm The blue LED is located at 'D11', the white is 'D12' Below is the before and after replacement of the LED's The new LED floods the lens. At any rate, it was more difficult to spudge the cases open than the LED's were to replace. There is a small amount of silicone type compund around the rim, and three interlocking standoffs on the case. Snapped back together as if they were happy. Before / after This whole thing started after running a CT of Unifi for the controller. They use a version of MariaDB that is no longer maintained, therefore the base OS cannot be updated without hacking together a system. There is a shell script someone came up with that Ubiquity is linking to, I was not entertained. Considering I've used the container to manage the AP's for a while I was ready to update some hardware. The UDM-SE wants to live in front of everything else, considering I'm a PfSense user, that was not going to happen. I gave it it's own physical LAN port on the Netgate 4100 in it's own VLAN, chose to set the DHCP to relay, nothing I've done so far allows the IP's the DHCP server in PfSense lease to the AP clients, to pass data through the UDM. Spanning tree refused to allow me entry to the UDM when setup this way. Turning off RSTP allowed access to UDM (but only from connecting to the UDM.) Loving level2. I'll need to segregate and run a PCAP while a client. So for now the UDM sits on the side in it's own VLAN corner, serving IP's to clients in it's own subnet. The double NAT doesn't seem to effect throughput by any noticeable difference.

-
I wasn't sure how to respond to this saddening news, took me a minute, so here's his laugh and smile for everyone. Whoever remembers what this was about ?
-
I went ahead with the ASUS RT-AX82U AX5400 Great price on that open box, It's for my Dad, updating from an older netgear, where they don't have all that many devices. If this thing gives him trouble I'll mimic my home network to some extent.
-
Yo, I'm looking for thoughts and infos on wireless routers, maybe mesh, maybe wifi 6 , help me decide.
-
Blue was always download and orange upload, maybe it’s me, been at it for 72 + hours or so.
-
Love the title ?
-
Yo @phred
-
Ha! I remember when Tommie and I would race to get our post counts up 😆 Wasn't too long before there was no way forward for me to catch up to him. We had our differences , but thats the way it goes sometimes, he’s one that would speak his mind and I liked that about him.
-
Everyone is doing well here still kickin around just no screamin. Sorry for not answering if you messaged on FB, lost access a couple years ago. Seems like every week we lose someone else, guess that happens as we get older. Hope everyone good on your end !
-
How did I possibly miss this! I'll marinate on this for a minute. What happened ? Can we go there ?
-
I left Windows OS after Vista came out, stuck in with XP until it was no longer super viable, I could never 'connect' with the direction they went. Though always have a VM to keep up that I can still use the basics of the OS. Linux / FreeBSD and MacOS have been way more exciting for me since then, where I can tweak it to what I want it to be. Good times either way!
-
-
Wow, pour one out
-
From Dodge City ,Kansas LTE atm, this is a laptop hitting the phones hotspot traceroute to dallas.testmy.net (45.32.203.96), 30 hops max, 60 byte packets 1 _gateway (172.20.10.1) 3.740 ms 5.916 ms 5.843 ms 2 130.sub-66-174-67.myvzw.com (66.174.67.130) 61.470 ms 74.303 ms 74.270 ms 3 * * * 4 66.sub-69-83-132.myvzw.com (69.83.132.66) 77.846 ms 77.801 ms 77.763 ms 5 * * * 6 200.sub-69-83-130.myvzw.com (69.83.130.200) 85.975 ms 31.239 ms 37.750 ms 7 136.sub-69-83-131.myvzw.com (69.83.131.136) 45.644 ms 50.517 ms 50.476 ms 8 137.sub-69-83-131.myvzw.com (69.83.131.137) 50.409 ms 77.054 ms 50.276 ms 9 0.ae3.BR3.CHI13.ALTER.NET (140.222.5.165) 61.268 ms 61.135 ms 61.059 ms 10 customer.alter.net (152.179.105.70) 45.062 ms 41.498 ms 53.552 ms 11 ae9.cr0-dal2.ip4.gtt.net (89.149.184.97) 73.244 ms 73.192 ms 73.153 ms 12 ip4.gtt.net (173.205.43.82) 67.023 ms 73.927 ms * 13 * * * 14 * * * 15 * * * 16 dallas.testmy.net (45.32.203.96) 58.835 ms !X 81.679 ms !X 87.254 ms !X
-
Key chatter ((((bouncing)) with membrane keyboard
mudmanc4 replied to mudmanc4's topic in Linux Help
kbdrate -r 32 -d 250 Improved the issue by a factor of 99.9% https://linux.die.net/man/8/kbdrate -
I'm a motor head who needs to learn something besides internal combustion.
mudmanc4 replied to Walley's topic in New Members
Another group goes up Sunday Feb 28 https://www.spacex.com/launches/ -
Key chatter ((((bouncing)) with membrane keyboard
mudmanc4 replied to mudmanc4's topic in Linux Help
Third keyboard now bouncing, yes the latest I'm typing on is a membrane, I can fiind nothing on the net about this issue. I suppose the issue could be with all three KBs however unlikely. -
This leads me to believe there is active software living on your network that you did not intend to be there. This is where I would start. SCP = Secure Copy Outside of any other programs / scripts on the (sending machine) SCP will allow a transfer to be done at full network speeds. Circumventing "throttling" script, Speaking locally at this point. Putty has an SCP client within https://www.putty.org/ A basic example for usage would be: scp file/location user@IPaddress:/directory or domain name Vs. IP You should also look into pscp Edit: ISP's use service such as https://www.sandvine.com/ for this purpose
-
Ubuntu 20.04 Gnome 3.36.8 I've been using a Matias FK302 since release, roughly ten years now, nearly flawless outside of the occasional bounce. Naturally as time goes on this got worse to the point i knew a cleaning / replacement was necessary. So I started the process with keycap soup: Then began opening the switches, they are simplified APLS SKBM clones with Matias tweaks. I've successfully cleaned these switches in the past so I knew what to expect, none the less I "successfully" bent a contact in the first switch opened after a quick clean, I was in a hurry, didn't bother to lube the slider even. The mount is metal, and is a bit rusty after ~ten years use and abuse, this along with the bent contact, are terms for a complete disassemble, new key switches soldered and paint. So I shelved the keyboard until after the holiday shipping tripe is completed, where I can be assured the switches will arrive un bastardised. < is that a word? So I went with a Lenovo 54Y9400 I had sitting around. A good membrane (rubber dome) keyboard widely used in data entry. First few days no issues. Now the real issue is rearing it's ugly head. But what is it? As I understand, rollover is programmed on board, as in keyboard. Yet when a keyswitch contacts bounce past the point of the programming, you clean / replace the switches. Simple, unless the logic board is borked. I've been fixing the double characters prior to this sentence, here is an example: TL;DR example on membrane KB: 1234567890))((.>??MMnNvcxxzASD you get the idea. This is on the Lenovo 544Y9400 membrane keyboard. [Searching] links me to mechanical switches why what and how toos, nothing about when a membrane KB does this, I've looking in /dev for ukbd to no avail, done a short bit of searching for the keyboard controller in Ubuntu, google is helping by assuming I'm working with a MIDI device. And eliminating all other interests several pages in. Thoughts, ideas?/ << nice bounce eh?/
-
Uhhg
-
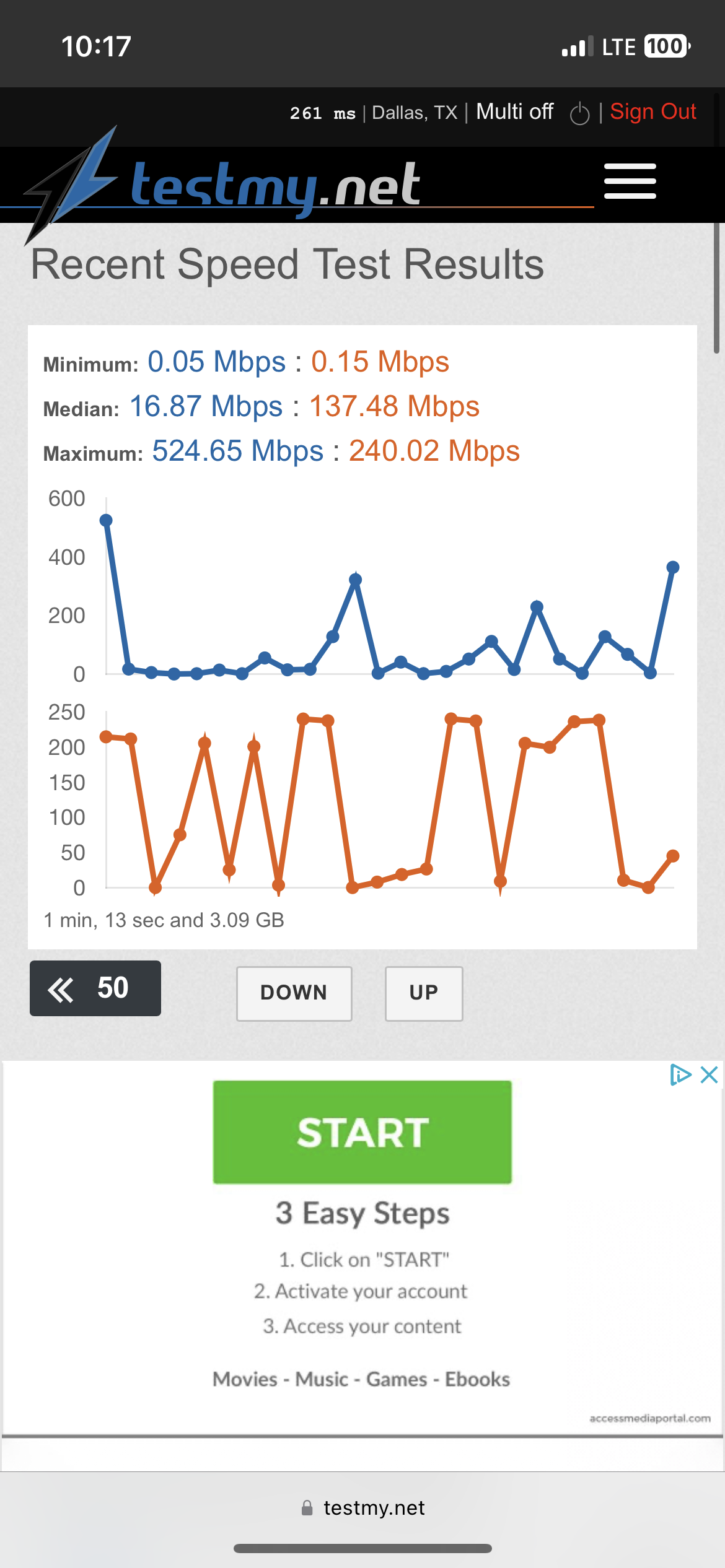
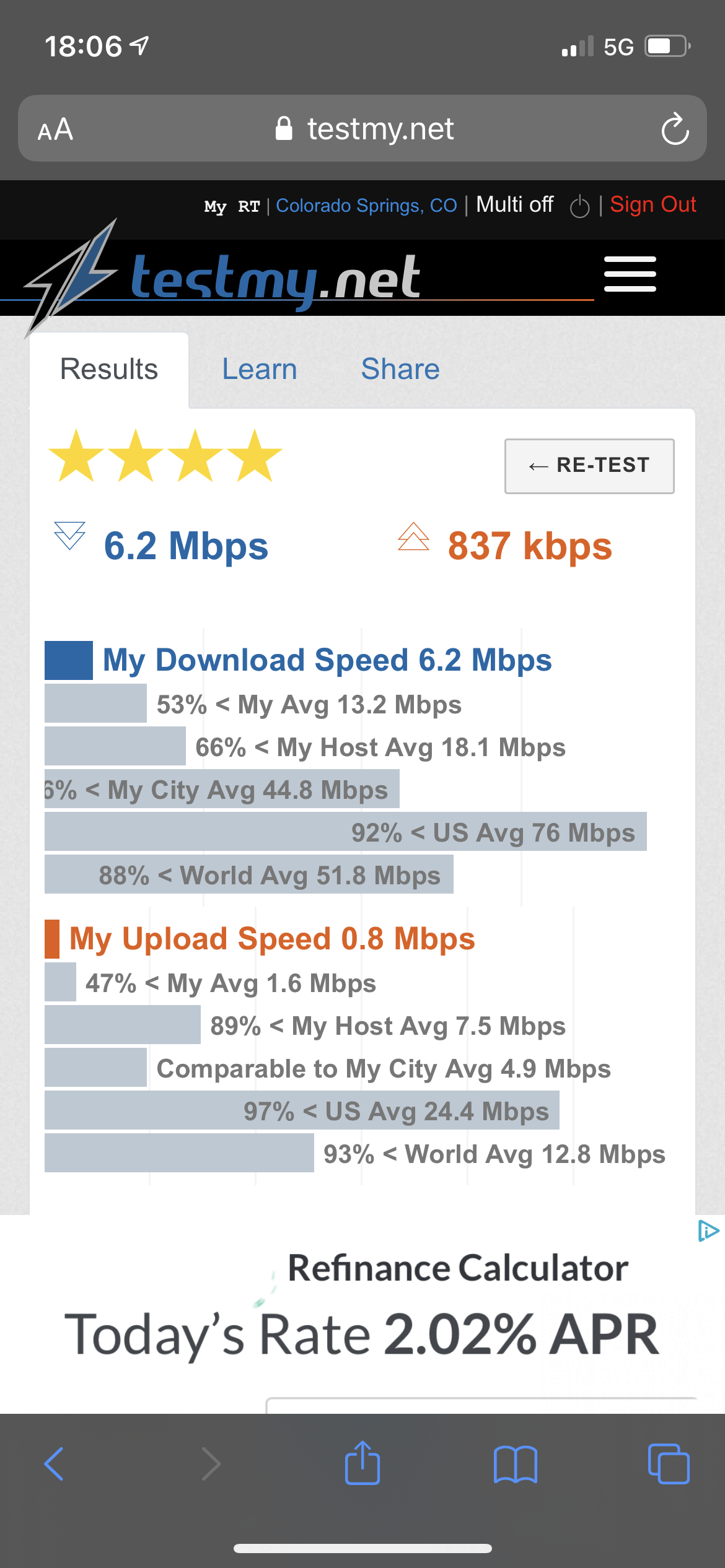
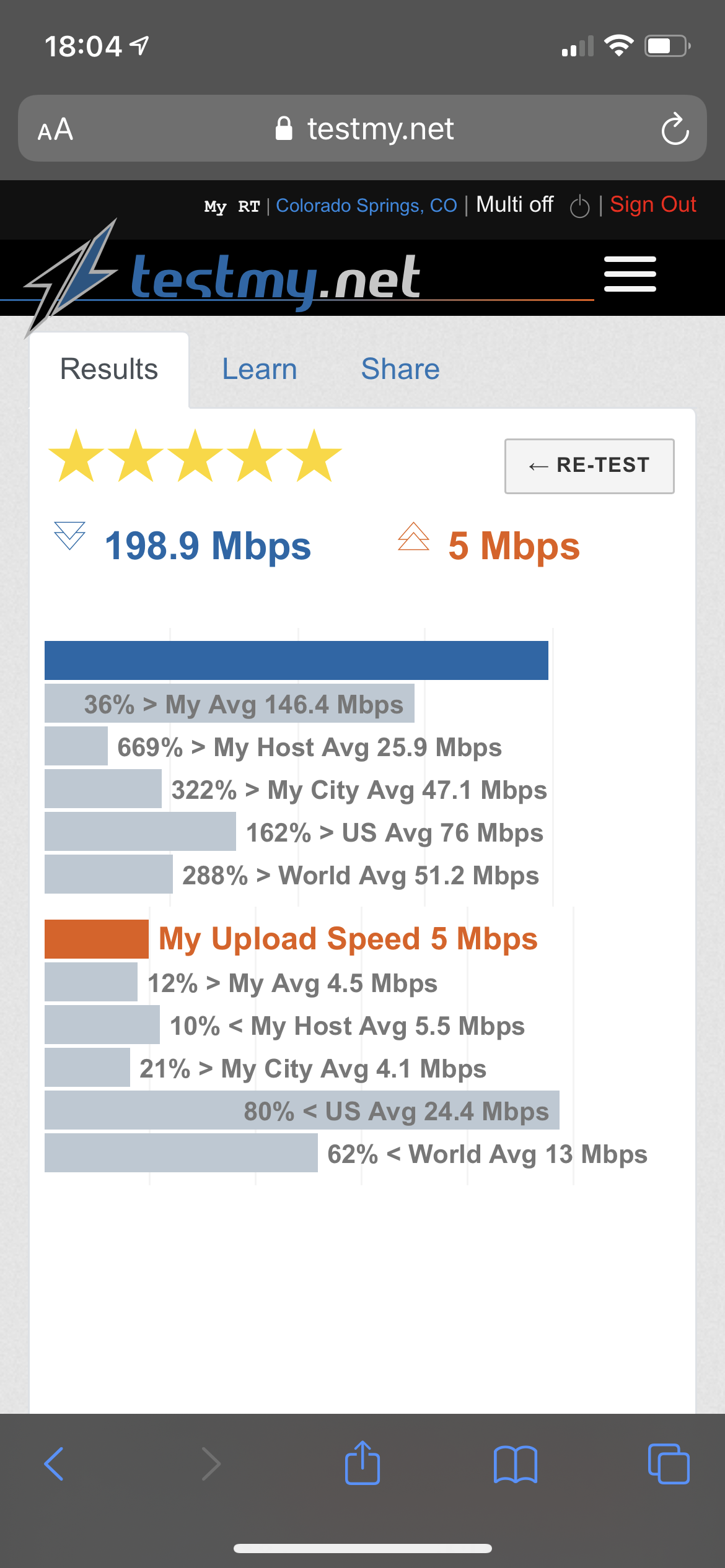
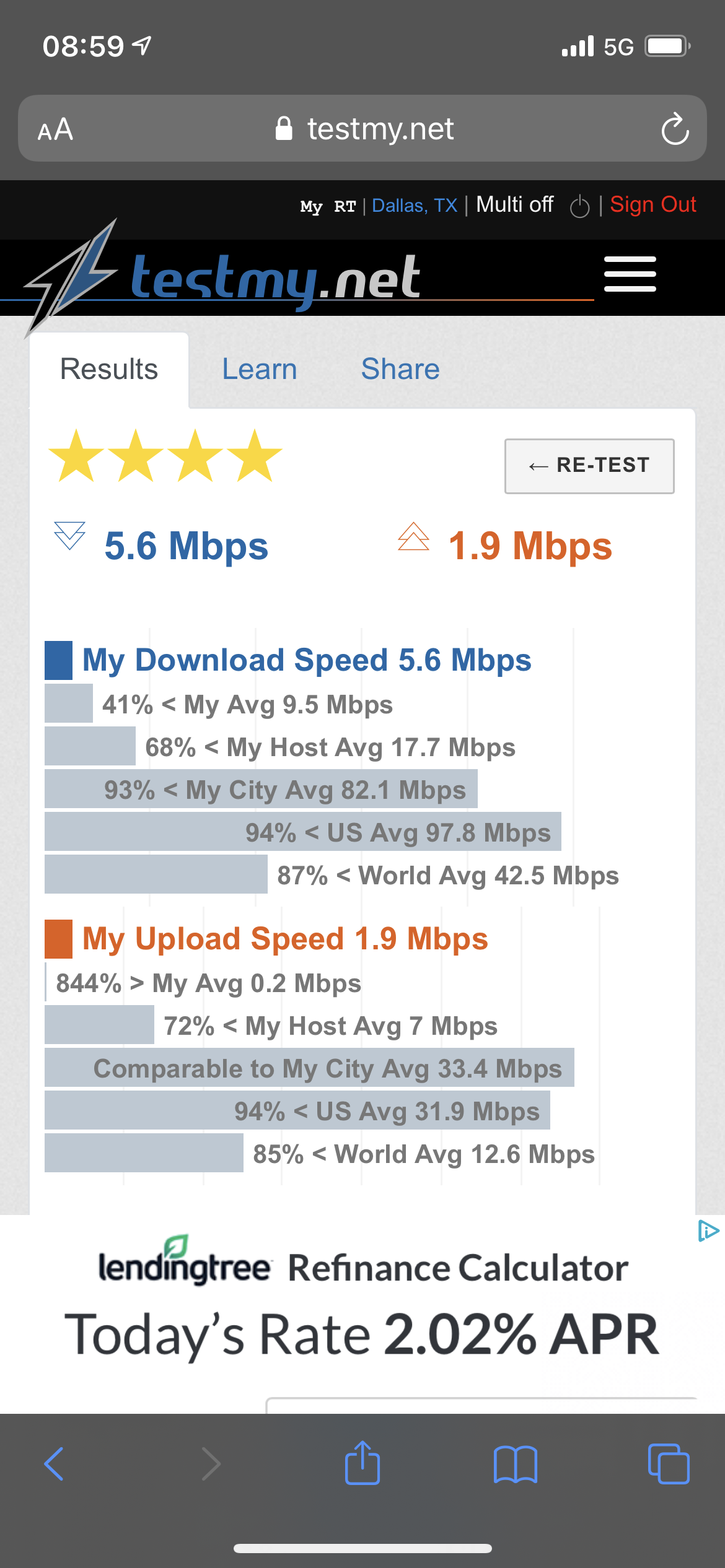
Notice the time, as well as the wireless or 5G indicators
-
Example which can be verified in the account at TMN:
-
more on this later